Langue: Français
Dans certains cas, vous pourriez vouloir collecter le nom d'une personne à la fois en alphabet latin et en alphabet arabe. Si vous avez un formulaire avec des champs de texte NAME_EN et NAME_AR, vous pouvez utiliser la formule de validation suivante pour vous assurer que seul l'anglais est saisi dans le premier champ :
REGEXMATCH(NAME_EN, "^[a-zA-Z ]+$")
Et cette formule pour vous assurer que seuls les caractères arabes sont utilisés :
REGEXMATCH(NAME_AR, "^[\u0600-\u06FF ]+$")
Définir la règle de validation
Dans le concepteur de formules, donnez au champ du nom arabe le code NAME_AR, puis cochez « Définir les règles de validation ». Copiez la formule ci-dessus dans l'éditeur de Règles de validation :
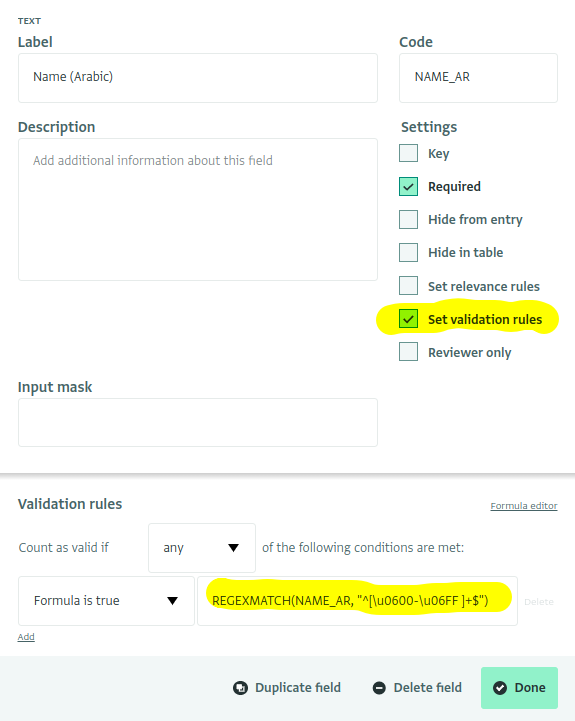
Blocs de code Unicode
Unicode est une norme pour la conversion des caractères et des symboles de la plupart des systèmes d'écriture du monde, couvrant 161 écritures modernes et historiques, ainsi que des symboles et des milliers d'émojis. Chaque caractère de presque toutes les langues se voit attribuer un numéro entre 1 et 1 114 112. La lettre « A » est le numéro 65, et la lettre arabe Alef (ا) est le numéro 1 536.
Pour faire référence à un point de code Unicode dans une expression régulière, vous utilisez le format \u0000 où le point de code est écrit en notation hexadécimale, plutôt qu'en décimale. En hexadécimal, la lettre A est \u0041 et l'Aleph arabe est \u0627.
L'Unicode est organisé en « blocs » pour chaque système d'écriture. Le bloc de code arabe commence par 0600, la plage se situe donc entre \u0600 et \u06FF.
Valider d'autres systèmes d'écriture
Vous pouvez utiliser la même logique pour exiger d'autres systèmes d'écriture, par exemple, le cyrillique, le grec ou le birman :
| Système d'écriture | Expression régulière |
|---|---|
| Grec | REGEXMATCH(NAME_GR, "^[\u0370-\u03FF ]+$") |
| Cyrillique | REGEXMATCH(NAME_CY, "^[\u0400-\u04FF ]+$") |
| Birman | REGEXMATCH(NAME_BU, "^[\u1000-\u109F ]+$") |