Language: English
In some cases, you might want to collect a person's name both in the Latin script and the Arabic script. If you have a form with text fields NAME_EN and NAME_AR, you could use the following validation formula to ensure that only English is entered into the first field:
REGEXMATCH(NAME_EN, "^[a-zA-Z ]+$")
And this formula to ensure that only Arabic characters are used:
REGEXMATCH(NAME_AR, "^[\u0600-\u06FF ]+$")
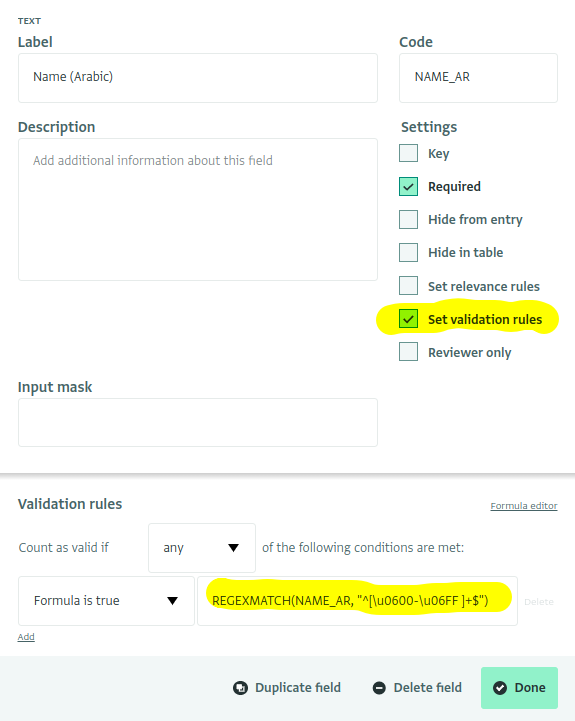
Setting the validation rule
In the formula designer, give the Arabic name field the code NAME_AR and then check "Set Validation rules". Copy the formula above into the Validation rules editor:
Unicode code blocks
Unicode is a standard for converting the character and symbols from most of the world's writing systems, covering 161 modern and historic scripts, as well a symbols, and thousands of emojis. Each character in nearly every language is assigned a number between 1 and 1,114,112. The letter "A" is number 65, and the Arabic letter Alef (ا) is number 1,536.
To refer to a unicode point in a regular expression, you use the format \u0000 where the codepoint is written using hexadecimal notation, rather than decimal. In hexadecimal, the letter A is \u0041 and the Arabic Aleph is \u0627.
The Unicode is organized into "blocks" for each writing script. The Arabic code block starts with 0600, so the range is between \u0600 and \u06FF.
Validating other scripts
You can use the same logic to require other writing scripts, for example, Cyrillic, Greek, or Burmese:
| Script | Regular expression |
|---|---|
| Greek | REGEXMATCH(NAME_GR, "^[\u0370-\u03FF ]+$") |
| Cyrillic | REGEXMATCH(NAME_CY, "^[\u0400-\u04FF ]+$") |
| Burmese | REGEXMATCH(NAME_BU, "^[\u1000-\u109F ]+$") |