Idioma: Español
En algunos casos, es posible que desee recopilar el nombre de una persona tanto en escritura latina como en árabe. Si tiene un formulario con campos de texto NAME_EN y NAME_AR, podría usar la siguiente fórmula de validación para asegurarse de que solo se introduzca inglés en el primer campo:
REGEXMATCH(NAME_EN, "^[a-zA-Z ]+$")
Y esta fórmula para asegurarse de que solo se usen caracteres árabes:
REGEXMATCH(NAME_AR, "^[\u0600-\u06FF ]+$")
Establecer la regla de validación
En el diseñador de fórmulas, asigne al campo del nombre en árabe el código NAME_AR y luego marque "Establecer reglas de validación". Copie la fórmula anterior en el editor de Reglas de validación:
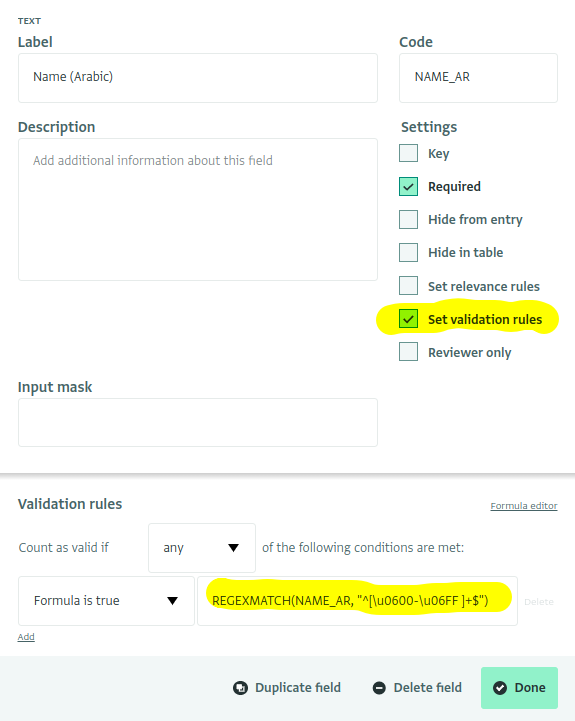
Bloques de código Unicode
Unicode es un estándar para la conversión de los caracteres y símbolos de la mayoría de los sistemas de escritura del mundo, que abarca 161 escrituras modernas e históricas, así como símbolos y miles de emojis. A cada carácter de casi todos los idiomas se le asigna un número entre 1 y 1.114.112. La letra "A" es el número 65, y la letra árabe Alef (ا) es el número 1.536.
Para hacer referencia a un punto de código Unicode en una expresión regular, se utiliza el formato \u0000, donde el punto de código se escribe en notación hexadecimal, en lugar de decimal. En hexadecimal, la letra A es \u0041 y el Aleph árabe es \u0627.
Unicode está organizado en "bloques" para cada sistema de escritura. El bloque de código árabe comienza con 0600, por lo que el rango está entre \u0600 y \u06FF.
Validación de otras escrituras
Puede usar la misma lógica para requerir otros sistemas de escritura, por ejemplo, cirílico, griego o birmano:
| Escritura | Expresión regular |
|---|---|
| Griego | REGEXMATCH(NAME_GR, "^[\u0370-\u03FF ]+$") |
| Cirílico | REGEXMATCH(NAME_CY, "^[\u0400-\u04FF ]+$") |
| Birmano | REGEXMATCH(NAME_BU, "^[\u1000-\u109F ]+$") |